The 47 Terabyte Exorcism: Summoning Block Storage from the Abyss

There’s a particular kind of hubris that comes from having a working cluster. Eighteen nodes across Austin, LA, Torrance, and Tokyo — all humming, all green, all connected over Tailscale. The observability stack was online. The zombie apocalypse had been quelled. Surely, deploying block storage would be the easy part.
It was not the easy part. What followed was a four-rite exorcism — casting out old kernel demons, resurrecting a broken network, building an organ system, and then teaching it to see.
The Case for LINSTOR
Every serious Kubernetes cluster eventually confronts the storage question. Longhorn had served its purpose, but its performance ceiling wasn’t going to cut it for what’s coming — SeaweedFS for distributed object storage, databases that need low-latency block devices, and AI workloads that can’t afford to wait.
LINSTOR, backed by DRBD 9 (Distributed Replicated Block Device), offered what I needed: kernel-level synchronous replication, thin provisioning via LVM, and a Kubernetes-native operator called Piraeus. DRBD replicates at the kernel level, LINSTOR orchestrates placement, and Piraeus handles the lifecycle.
| Pool | Nodes | Capacity | Media |
|---|---|---|---|
| pool-sata | 6 RPi nodes | ~10.9 TiB | USB SSD (sda3 partitions) |
| pool-nvme | 5 GPU nodes | ~36.4 TiB | 8TB WD BLACK SN850X |
| Total | 11 storage nodes | ~47.3 TiB |
Plus 7 diskless satellites that mount DRBD volumes remotely. Simple, right?
Rite I: Banishing the Old Blood
Every exorcism begins the same way — you discover the host is already possessed.
Piraeus v2 has an elegant design: apply a LinstorCluster resource, satellites deploy on every node, and each runs a drbd-module-loader init container that compiles DRBD 9 from source against your kernel headers. No pre-built packages, no version mismatches. Beautiful — unless your nodes are already haunted.
1
version: 8.4.11 (api:1/proto:86-101)
DRBD 8. Baked into the Raspberry Pi OS kernel, auto-loaded on boot, squatting in memory like an ancient spirit that refuses to leave. The Piraeus module loader saw it, shrugged, and refused to compile DRBD 9. The first exorcism was simple — unload the demon, salt the earth:
1
2
sudo rmmod drbd
echo "blacklist drbd" | sudo tee /etc/modprobe.d/blacklist-drbd.conf
Added to the Ansible storage prep playbook so every reboot doesn’t resurrect it. With DRBD 8 banished, the module loader compiled DRBD 9.2.16. On GPU nodes — 30 seconds. On the 2GB RPi? Two cups of coffee.
But the old blood ran deeper in two machines.
The DGX — 128GB RAM, NVIDIA GPU, crown jewel of the cluster — refused the new module entirely:
1
insmod: ERROR: could not insert module ./drbd.ko: Key was rejected by service
Secure Boot. The DGX only loads signed kernel modules, and Piraeus compiles unsigned ones. No amount of configuration would fix this — I walked to the machine, entered BIOS, and disabled Secure Boot. A physical exorcism for a digital demon.
The security node, running Kali Linux, had the most insidious possession. The LINSTOR satellite was fine — online, storage pool healthy. But the CSI node pod kept crashing. Liveness timeouts? Checked. Firewall? Clear. AppArmor in complain mode? Confirmed. Then strace found the spirit hiding in the socket:
1
connect(3, {sa_family=AF_UNIX, sun_path="/csi/csi.sock"}, 16) = -1 EACCES (Permission denied)
The kernel audit log showed AppArmor entries marked ALLOWED with denied="create". In complain mode. Kali’s kernel was enforcing restrictions it claimed to only be logging. The only reliable fix was nuclear — apparmor=0 in the kernel command line. Hours of debugging, one kernel parameter.
Three different possessions, three different rites. DRBD 8 needed a blacklist. Secure Boot needed a BIOS visit. Kali’s AppArmor needed a kill switch. Each node had its own demon.
Rite II: Resurrecting the Network
With the kernel demons banished, satellites started appearing. Three, then five, then… they stopped. Half the cluster couldn’t register. DNS lookups for the LINSTOR controller timed out.
The diagnosis was grim. CoreDNS: one replica, for a cluster spanning three countries. And the VXLAN overlay it depended on was shattered:
1
2
$ ip link show flannel.1
Device "flannel.1" does not exist.
Gone. On 13 of 18 nodes.
K3s uses Flannel with --flannel-iface=tailscale0 to build VXLAN on top of Tailscale. But if K3s starts before Tailscale establishes its interface, Flannel quietly gives up. Thirteen nodes had rebooted, and K3s won the race on every one. The overlay was dead, DNS was dead, and service discovery was dead with it.
1
systemctl restart k3s-agent 2>/dev/null || systemctl restart k3s
Flannel.1 reappeared within seconds. CoreDNS scaled to 3 replicas. But the five GPU nodes — the ones with 36 terabytes of NVMe — were still absent.
GPU nodes carry a amd.com/gpu=true:NoSchedule taint to keep non-GPU workloads away. Noble intention, wrong target — LINSTOR satellites are infrastructure, not GPU workloads. The taint was blocking them like a ward on a door:
1
2
3
4
5
spec:
tolerations:
- key: amd.com/gpu
operator: Exists
effect: NoSchedule
The ward broken, thirty-six terabytes of NVMe flooded the pool. Eighteen satellites, 47.3 terabytes, all online. The skeleton was assembled.
Rite III: The Circulatory System
Raw block storage is just a skeleton — it needs a circulatory system. MinIO had been the cluster’s blood supply: a single NAS node with four 3.5TB disks, no HA, bus factor of one. SeaweedFS would replace it — a distributed object store spanning regions, backed by the LINSTOR block storage we just resurrected.
1
2
3
4
Masters (x3, Raft consensus) → block-sata PVCs
Volume Servers HA (x3) → block-sata PVCs (DRBD-replicated)
Volume Server Archive (x1) → NAS blob-disks (4x 3.5TB, ~14 TiB)
Filer + S3 Gateway (x2) → block-sata PVCs
Deployment went sideways immediately. LINSTOR’s default StorageClass uses 2 replicas plus a diskless tie-breaker for quorum — but the tie-breaker hit a Java race condition on GPU nodes. The lateral fix: SeaweedFS Raft provides its own consensus, so DRBD underneath the masters is redundant. A new block-sata-single StorageClass with 1 replica and no tie-breaker let SeaweedFS handle its own HA.
Then the Raft bootstrap paradox. Three masters, podManagementPolicy: Parallel, all three started simultaneously, found nobody, and each initialized independent single-node clusters. Three Raft clusters that can never merge — consensus doesn’t work in reverse.
Fix: OrderedReady. But master-1 still couldn’t find master-0 — because the headless service only publishes ready pods, and master-0 couldn’t be ready without the quorum it couldn’t form without master-1. A perfect deadlock: DNS needs Ready, Ready needs Raft, Raft needs DNS.
1
2
spec:
publishNotReadyAddresses: true
One line broke the circle. If you deploy any consensus protocol on Kubernetes — etcd, Raft, ZooKeeper — burn this into your templates.
Even then, the liveness probe kept killing masters during elections. It checked /cluster/status, which returns HTTP errors when no leader exists. Kubelet saw errors, killed the pod, which restarted the election, which the probe killed again. Democracy in an infinite loop. Fix: tcpSocket — the process was alive, it just hadn’t elected a leader yet.
Finally, with nine pods running and 8 S3 buckets created, Loki stopped authenticating. The Ansible playbook injected real S3 credentials into a ConfigMap, but the filer manifest also defined the same ConfigMap — with placeholder values. Last kubectl apply wins, and the wrong writer always goes last.
The circulatory system was alive: HA tier on DRBD-replicated PVCs, archive tier on the NAS blob-disks, S3 gateway on port 8333. Mimir and Loki redeployed against SeaweedFS. MinIO’s namespace deleted. Its playbook archived.
The data pipeline: OTel Collector → Mimir/Loki → SeaweedFS → LINSTOR → DRBD → disk. Block storage all the way down.
Rite IV: Giving It Eyes
A body without eyes is just meat. The observability stack was collecting data, but SeaweedFS itself was a black box — no metrics, no dashboards, no alerts. Four manifests updated with -metricsPort=9325 and Prometheus scrape annotations. The OTel Collector auto-discovered them within minutes.
Then I opened Grafana. SeaweedFS panels: beautiful. Node metrics: blank. Container metrics: blank.
The asymmetry was the clue. SeaweedFS pods serve unauthenticated HTTP metrics. Kubelet metrics require a bearer token — and the collector didn’t have one. Every scrape silently returned 401, logged a useless warning, and moved on. Half the monitoring stack was blind and nothing complained about it.
One line — authorization.credentials_file pointing to the service account token — and node metrics flooded in. A separate /metrics/cadvisor job brought containers online. The eyes opened.
And then the nervous system collapsed.
Eighteen nodes of cadvisor metrics is a cardinality explosion — thousands of series per node, hundreds of labels, millions of data points per scrape cycle squeezed into 512Mi of memory. The collector crashed, restarted, scraped everything again, OOM’d again. 126 restarts overnight. Thirteen hours of metrics, gone — not because anything was wrong with the cluster, but because the thing watching it ran out of memory watching.
The fix: filter cadvisor to the 8 metrics dashboards actually use, bump memory to 1.5Gi, drop from 2 replicas to 1 (Prometheus SD doesn’t shard — replicas just duplicate work), kill the logging exporter. Post-fix: 890Mi peak, stable.
The credential stomp returned too — re-applying SeaweedFS manifests for metrics annotations also re-applied the filer’s ConfigMap with placeholder S3 credentials. Same demon, second summoning. This time the exorcism was permanent: the ConfigMap was removed from the manifest entirely. If Ansible owns the secret, the manifest doesn’t get an opinion.
Grafana itself needed its own rites. Recreate deployment strategy for its ReadWriteOnce PVC (rolling updates deadlock when two pods fight over one volume). Sidecar-loaded dashboards: SeaweedFS cluster health, node metrics with region filters, workload metrics with namespace selectors. Seven alert rules wired to email — node down, collector down, high memory, crashloops, Raft leader loss, S3 errors, OOM kills.
The final touch: Traefik Ingress with Let’s Encrypt TLS (DNS-01 via Cloudflare — no public HTTP needed), DNS records across both internal Technitium clusters and Cloudflare. The cluster’s eyes now live at a clean HTTPS domain — no more typing Tailscale IPs and port numbers into a browser like an animal. The DNS points to Tailscale IPs, so it’s only reachable from the tailnet.
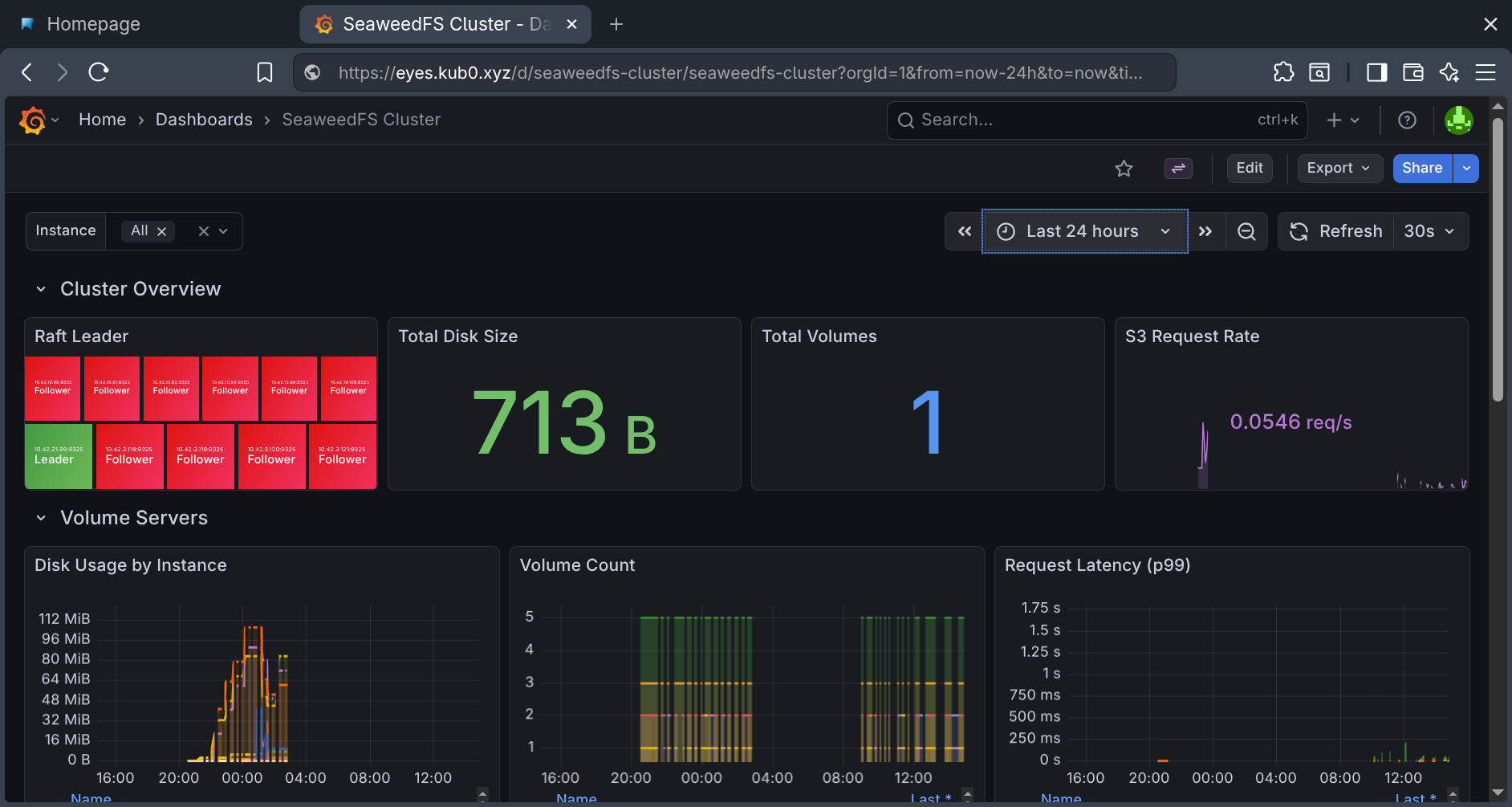 The custom SeaweedFS dashboard: volume server disk usage, S3 request rates, Raft leader status, and resource consumption across all nine pods.
The custom SeaweedFS dashboard: volume server disk usage, S3 request rates, Raft leader status, and resource consumption across all nine pods.
Rite V: Building the Skin
A body with eyes, bones, and blood still isn’t usable if you can’t touch it. Every service had a different Tailscale IP and port number scrawled in a notes file. Grafana was 100.x.y.z:3000. SeaweedFS was 100.a.b.c:8333. The Technitium instances — one in Torrance, one in Tokyo — were raw IPs on port 5380. Operating this cluster felt like navigating a city by GPS coordinates instead of street names.
The skin needed three layers: a DNS management system, TLS everywhere, and a portal to tie it all together.
First, a unified DNS script that writes A records to all three providers simultaneously — both Technitium instances and Cloudflare. One command creates a subdomain across the entire DNS infrastructure. The Cloudflare records exist for cert-manager’s DNS-01 challenges (Let’s Encrypt doesn’t care that the IPs are unreachable from the public internet — it validates via TXT records). The Technitium records handle actual resolution inside the tailnet.
Then Traefik Ingresses with cert-manager annotations. Each service gets an Ingress, cert-manager sees the letsencrypt-prod annotation, creates a DNS-01 challenge against Cloudflare, and provisions a real TLS certificate. No self-signed warnings, no port numbers, no IP addresses.
The two Technitium DNS servers — bare metal, running in Docker outside K3s — got proxied in via Kubernetes external Services with manual Endpoints. Traefik sticky sessions keep the web UI login stable (Technitium’s session state doesn’t survive being load-balanced between instances). Each instance got its own subdomain: dns-toa for the single-site Torrance instance, dns-hnd for the Tokyo instance that serves Tokyo, Austin, and LA.
The Kubernetes Dashboard project had been retired to kubernetes-retired/ while we weren’t looking — its Helm repo returns 404. Headlamp, now under kubernetes-sigs, replaced it cleanly. Same purpose, active maintenance, simpler deployment.
Finally, Homepage — a Next.js dashboard with native Kubernetes API integration — became the portal at console.kub0.io. It auto-discovers services via Ingress annotations, shows live cluster CPU/memory stats, and monitors service health with status indicators. Four categories: Observability, Storage, Networking, Kubernetes. Every service one click away, all over HTTPS, all behind Tailscale.
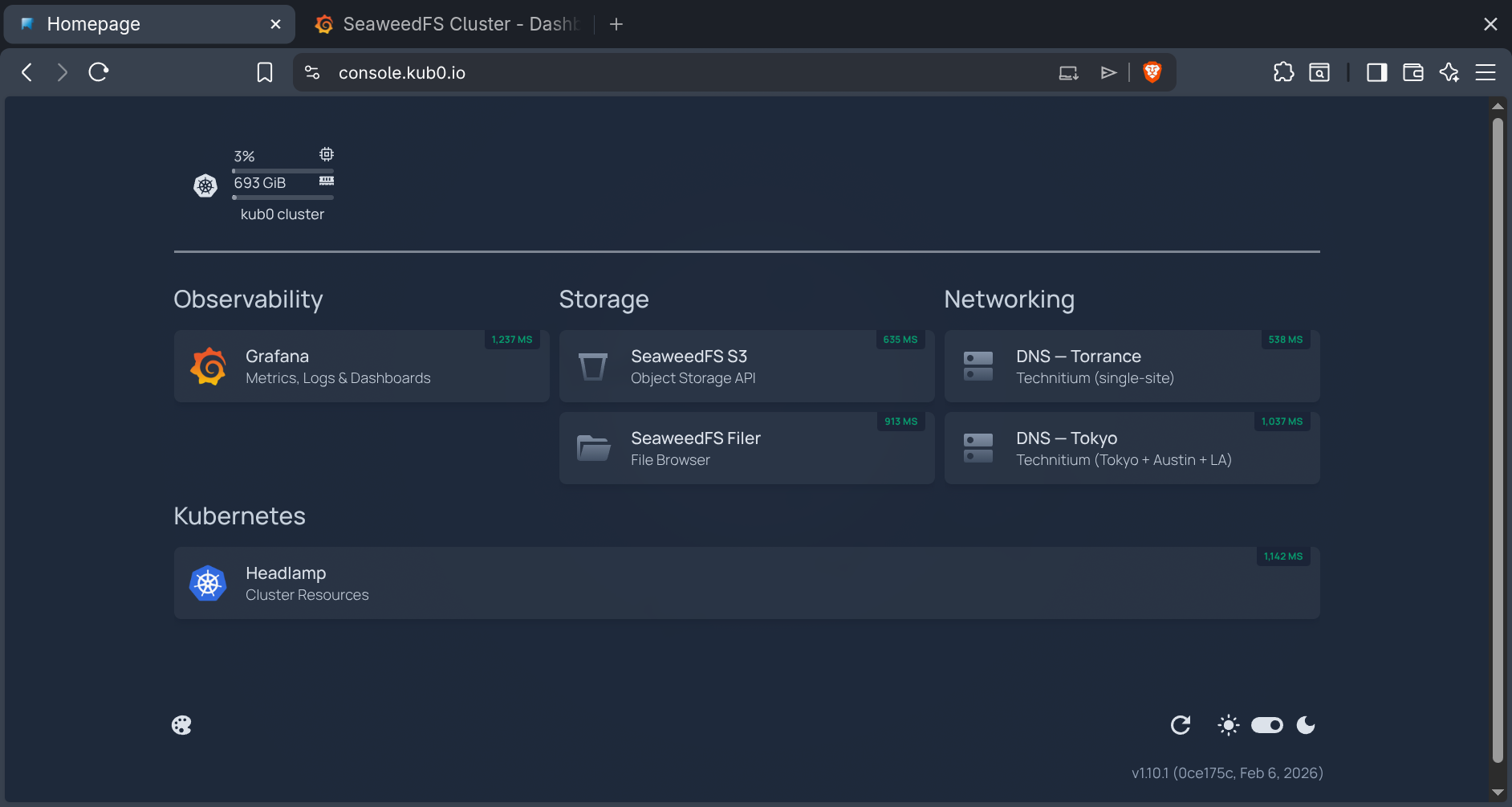 The Homepage console: centralized location for core services and widget from Headlamp on cluster stat.
The Homepage console: centralized location for core services and widget from Headlamp on cluster stat.
| Subdomain | Service |
|---|---|
| console.kub0.io | Homepage Portal |
| eyes.kub0.xyz | Grafana |
| s3.kub0.xyz | SeaweedFS S3 |
| files.kub0.xyz | SeaweedFS Filer |
| dns-toa.kub0.xyz | Technitium DNS (Torrance) |
| dns-hnd.kub0.xyz | Technitium DNS (Tokyo) |
| kube.kub0.xyz | Headlamp |
Seven subdomains, seven TLS certificates, zero exposed ports. The cluster went from a collection of IP:port combinations to something that feels like a private cloud console. GCP at home — if GCP ran on Raspberry Pis and a DGX in your closet.
The Exorcist’s Toolkit
This entire deployment was done with Claude Code running in my terminal — not as a chatbot for advice, but as a fellow exorcist. Reading playbooks, running kubectl, analyzing strace output, editing YAML, iterating through fixes in real-time.
When strace revealed EACCES on the unix socket, Claude exec’d into the container, compared inodes across mount namespaces, and traced the failure through the kernel audit log. When flannel.1 vanished on 13 nodes, it proved the VXLAN layer was broken with tcpdump before suggesting the restart. When the OTel Collector was OOM-looping overnight, it identified the cadvisor cardinality explosion, wrote the metric filter, and tuned the memory limits — all without leaving the terminal.
It makes mistakes and needs course corrections. But having a pair programmer that holds the entire context of an 18-node cluster in memory — kernel quirks, Ansible state, and Kubernetes manifests simultaneously — turns what would be days of debugging into hours.
The Rites, Summarized
The old blood must be banished first. DRBD 8, Secure Boot, Kali AppArmor — each node had its own demon. Blacklist, BIOS, kernel parameter.
Flannel over Tailscale is a race condition. If K3s boots before Tailscale, the VXLAN overlay dies silently. Restart K3s, scale CoreDNS.
GPU taints block infrastructure. Storage satellites need tolerations. Noble protections, wrong targets.
Consensus protocols need
publishNotReadyAddresses. DNS needs Ready, Ready needs consensus, consensus needs DNS — break the circle.Liveness probes should check life, not health.
tcpSocketduring elections. HTTP checks kill what they’re protecting.One resource, one owner. If Ansible owns the secret, the manifest doesn’t get to define it. The last writer wins, and it’s always wrong.
Application-level HA makes block replication optional. SeaweedFS Raft doesn’t need DRBD underneath.
cadvisor will eat your collector alive. Filter to the metrics you actually use. Unfiltered, 18 nodes will OOM any reasonably-sized collector.
RWO PVCs and rolling updates deadlock. Use
Recreate. Both pods fight over one volume.The Kubernetes Dashboard is dead.
kubernetes.github.io/dashboardreturns 404. The project moved tokubernetes-retired/. Headlamp underkubernetes-sigsis the replacement.Sticky sessions for stateful web UIs behind a proxy. Technitium’s login breaks when requests bounce between instances. Traefik sticky cookies fix it.
2GB control plane nodes will surprise you. The OTel Collector alone can eat 1.1GB. Add a Mimir distributor and the control plane, and a 2GB RPi goes NotReady from memory pressure. Scale down or move workloads off resource-constrained controllers.
The cluster now has a skeleton (LINSTOR), a circulatory system (SeaweedFS), eyes (Mimir), a voice (Loki), a nervous system (OTel Collector), and skin (Traefik + cert-manager + Homepage) — all accessible through a single portal at console.kub0.io, behind Tailscale, with real TLS certificates. The 47 terabytes aren’t raw capacity anymore. They’re the body of something alive, monitored, addressable, and waiting to be fed.
Next: ADS-B feeder pipelines pulling aircraft telemetry from SDR receivers, CCTV ingestors archiving camera feeds into SeaweedFS, and real data powering kub0.ai. The storage is ready. The eyes are open. The skin is sealed. Time to give this thing something real to look at.