The Great API Mirage: When 'Ready' is a Lie
In which we discover that the Kubernetes API is a hopeless optimist, the Linux kernel holds grudges, and the last layer of defense is always a person with a keyboard.
There is a specific kind of dread that only a systems engineer knows. It’s the feeling you get when every dashboard is green, every pod is "Running," and every health check says "Ready"—but absolutely nothing is actually working.
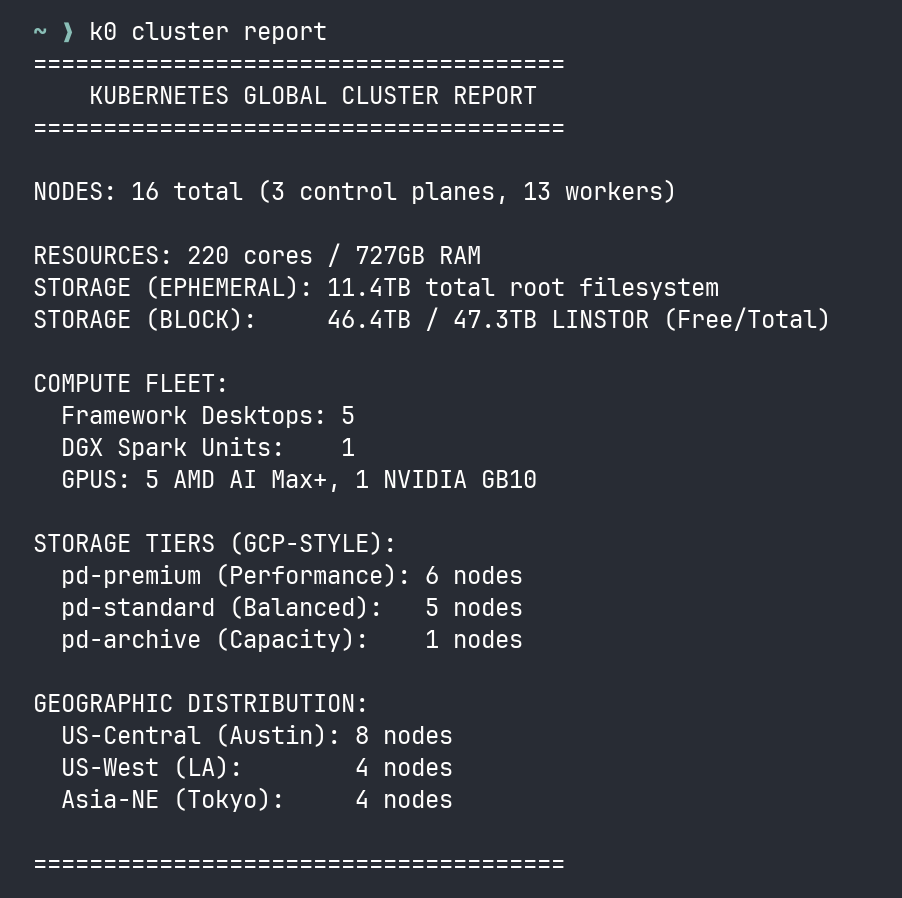
In the aftermath of our massive Headscale migration, I hit that wall. We had the Sentinel Protocol live. We had k0 monitoring the grid. We had just upgraded the entire HA Spine to K3s v1.34.5.
On paper, the cluster was perfect. In reality, it was suffering from a total functional collapse of the data plane. We had hit the Great API Mirage.
Act 1: The Liar in the Kubelet
It started with Mimir. Our metrics storage began throwing i/o timeout warnings during memberlist gossip. Then OpenBao, the cluster’s high-security vault, started failing liveness probes.
I ran k0 cluster health. Nodes Ready: 17/17.
I ran kubectl get pods. Running. Running. Running.
This is the first lesson of the Mirage: The Kubernetes API is an optimist. The Kubelet only cares if the process is heartbeating over the management lane (Headscale). It is blissfully unaware that the data plane (Flannel/VXLAN) has checked out of reality and is currently blackholing every packet destined for another region. The cluster was "Ready" to the API, but partitioned at the kernel.
Act 2: The Service File Massacre
How did we get here? We followed the standard operating procedure for a K3s upgrade: curl -sfL https://get.k3s.io | sh -. It’s the industry standard. It’s also a tactical trap. What the documentation forgets to mention is that the installer is an alpha-predator—it overwrites your custom systemd service file with zero remorse.
Our control plane service files had been carefully tuned for the Headscale mesh:
1
2
3
4
5
6
7
8
9
# What we had (The Truth):
ExecStart=/usr/local/bin/k3s server \
'--node-ip=100.67.x.y' \
'--advertise-address=100.67.x.y' \
'--flannel-iface=tailscale0' \
'--resolv-conf=/etc/rancher/k3s/resolv.conf'
# What we got after curl | sh (The Lie):
ExecStart=/usr/local/bin/k3s server
Everything gone. The Genesis node was suddenly advertising its LAN IP instead of its Headscale IP. etcd tried to peer across a network that didn’t exist.
And then the second gotcha hit: without --resolv-conf=/etc/rancher/k3s/resolv.conf, K3s regenerated the CoreDNS configmap with forward . /etc/resolv.conf. On nodes running systemd-resolved, that points to the stub resolver at 127.0.0.53—which loops back into the pod network that was already dead. We weren’t just partitioned; we had poisoned our own DNS.
Act 3: The VTEP Collapse
As we scrambled to stabilize etcd, the maintenance playbook rolled through the agent fleet on schedule. It didn’t know the CPs were compromised—it just did what it always does: drain, update, restart, uncordon.
The playbook was correct. The timing was catastrophic.
The agents flushed their Forwarding Database (FDB) tables on restart, but the CPs—still reeling from the service-file massacre—weren’t advertising fresh VTEP entries for them to learn from.
The result was a Total VTEP Collapse. 15 of 16 LINSTOR satellites went OFFLINE instantly. Pod-to-pod networking was severed.
1
2
$ linstor node list | grep -c OFFLINE
15
The only satellite that survived was the one on the Genesis node, because it was the only one whose CP had been manually corrected.
Act 4: The Gossip Storm
Mimir’s memberlist gossip uses TCP. With the overlay partitioned, gossip packets between regions timed out—but not consistently. Small packets made it through while large TLS certificates didn’t. This created a "partially partitioned" state where nodes could see some peers but not others.
The ring constantly recalculated membership, creating a CPU spike that pinned our RPi4 nodes at 85% utilization as they tried to figure out who was still alive in the wreckage.
Act 5: The Recovery Protocol
We fixed it by enforcing the Protocol. No more guessing. No more "restarting the world." We followed the natural laws of the mesh:
- Control Planes First: We manually restored the service files and kicked the K3s service on the HA Spine nodes sequentially. This forced the regeneration of the VTEP announcements.
- Wait for Quorum: We didn’t touch an agent until etcd reached a stable 3-node majority.
- Agents Follow: Once the CPs were telling the truth again, the agents re-learned the topology automatically. No manual intervention required.
1
2
3
4
5
# The correct sequence (Serial, CPs first)
for cp in toa-fwd-gpu-01 aus-fwd-gpu-01 lax-fwd-gpu-01; do
ssh $cp "sudo systemctl restart k3s"
sleep 30 # wait for etcd to stabilize
done
Crucially, the training run on our DGX never even noticed the fire. It had been submitted via KubeRay, but the actual training process—once dispatched to the GPU node—ran independently of the pod network. It calmly fine-tuned a 120-billion parameter model while the Kubernetes dimension was in a state of civil war.
Resilience isn’t about choosing containers or bare metal. It’s about ensuring your critical workloads don’t share a failure domain with your control plane.
Act 6: The Insurance Policy
A week later, we ran routine maintenance. The playbook drained nodes, applied updates, rebooted. Every node came back—except the Genesis node in Torrance.
Ping: nothing. SSH: timeout. Nebula: dead. Headscale: dead. The node was powered on—an employee confirmed it—but it wasn’t on any network. It had booted, hit a filesystem check prompt, and was sitting in a windowless office asking Fix? (y/n) to a room full of travel brochures.
This is the third lie. The first lie was Kubernetes telling us nodes were Ready. The second was the service file installer pretending it didn’t destroy anything. The third is Linux, sitting at a prompt on a headless machine with no monitor, no keyboard, no remote management, waiting for a human who doesn’t know it’s waiting.
We diagnosed it from Tokyo at 2am. The GRUB config was TIMEOUT=0 with hidden style—it boots instantly, no menu. The kernel was fine (identical hardware at another site was running the same version). The only explanation was fsck finding a dirty journal from the reboot and refusing to continue without confirmation.
The fix was a phone call. Not to a datacenter. Not to a NOC. To K, an employee at the travel agency that hosts the server, who doesn’t know what Linux is and doesn’t need to.
1
2
3
4
5
6
7
8
1. パソコンの裏側にUSBキーボードを差す
2. 電源ボタンを長押し(5秒以上)して完全に電源を切る
3. 10秒待つ
4. 電源ボタンを押して電源を入れる
5. 1分待つ
6. Y → Enter を 3回繰り返す
7. 30秒待つ
8. もう一度 Enter を押す
No monitor. No diagnostics. Just a blind keyboard sequence at 9:30 on a Monday morning. K plugged in the keyboard, pressed the keys, and walked away. The node came online 45 seconds later. etcd recovered to 3/3 quorum. The API server stopped flapping. Hermes went green.
We wrote three layers of insurance that afternoon:
Layer 1: Don’t create the problem. The reboot playbook now polls /proc/drbd and waits for all volumes to finish syncing before issuing the reboot command. A dirty DRBD shutdown is how you get a dirty filesystem, and a dirty filesystem is how you get an invisible prompt.
Layer 2: If it happens, fix it silently. We pushed fsck.mode=force fsck.repair=yes to the GRUB config on every x86 node in the fleet. No reboot required—it takes effect on the next boot, whenever that is. The node will never ask a question nobody can answer again.
Layer 3: If all else fails, reach the power. A smart plug is on order. Fifteen dollars for remote power cycling from anywhere in the world. Though in this case, it wouldn’t have helped—the machine was on, just stuck. Sometimes the fix is a person with a keyboard.
The uncomfortable truth is that we could automate everything—the VTEP recovery, the etcd quorum, the DNS poisoning fix, the DRBD sync gates—and still get stopped by a three-letter prompt on a machine with no screen. The cluster had survived a total data plane collapse, a control plane massacre, and a gossip storm. It was taken down by fsck asking for permission.
The Mesh Imperatives
| Rule | Why |
|---|---|
Avoid curl \| sh on custom nodes | The installer is a vandal; it will wipe your --node-ip and your dignity. |
| Spine First, Limbs Second | Restart CPs before agents. The agents are only as smart as the VTEP ads they receive. |
| Verify the Auxiliaries | A missing --resolv-conf poisons CoreDNS as effectively as a bad config. |
| The “Ready” Signal is Propaganda | If you don’t audit the kernel bridge fdb, you’re just reading API poetry. |
| Headless nodes need silent boots | fsck.repair=yes or accept that your cluster’s fate rests on someone answering a prompt nobody can see. |
| The last layer is always human | Automate everything. Then put a keyboard in the server closet. |
The ghosts are purged. The kernel is clean. K has no idea what he fixed, and that’s exactly how it should be.