The Differentiation: When Agents Stop Being Generic
There’s a version of the multi-agent story that stops too early. You have a task queue. You have agents polling it. They claim work, do it, push PRs. The loop closes. You call it done.
That version has a problem: every agent is the same agent. Same context, same knowledge, same instincts. The first agent to work on a networking issue learns nothing that the second one carries forward. The security-focused work and the blockchain work and the Go API work all run through the same undifferentiated process, each session starting cold.
Generic agents are capable. Specialized agents are something else. The differentiation between them is the story of what happened after the dispatcher came online.
Project Gaius
The dispatcher — covered in the previous post — solves coordination: scope locks, conflict detection, automated merging. It’s the traffic layer. What it doesn’t solve is memory.
When a session ends, everything the agent learned dies with it. An agent discovers an undocumented dependency, confirms a failure mode, finds the command that actually fixes the problem — and that knowledge exists nowhere except the session transcript. The next agent working in the same area starts from scratch.
Project Gaius is the memory layer built to solve this. It has two responsibilities: session lifecycle and domain file maintenance.
On the session side, Gaius mines completed Claude Code sessions — dense JSONL files that accumulate over hours of agent work — and extracts structured signal: decisions made, mistakes logged, operational discoveries. That signal gets staged, reviewed, and promoted into domain files that persist in the agent-memory repository.
On the injection side, those domain files are what the orchestrator bundles into every claim response. An agent claiming a scope:networking task wakes up with the networking domain file already loaded — current tunnel configuration, MTU gotchas, QUIC constraints, every hard-won fact from every agent that worked that domain before it. The knowledge survives the session because Gaius extracted it and put it somewhere the next agent can find it.
The result is a system where agents compound rather than repeat. Each session enriches the domain files. Each enriched domain file makes the next agent more capable. The loop improves through operation, not retraining.
Note: This post describes the architecture as it operates today. Gaius is under active development — a dedicated post covering the full system design is coming separately.
What the Scope System Actually Does
The orchestrator’s scope conflict check is usually described as a concurrency primitive — it prevents two agents from touching the same layer of a repo at the same time. That’s accurate. But it’s underselling what scope labels are.
When an agent claims a task, the claim response includes the task metadata, the conflict graph, and — since the context injection phase — the domain files matching the task’s scope labels. A scope:networking task ships the networking domain file: current tunnel configuration, DNS topology, Tailscale quirks, the Mullvad proxy pool rules. A scope:storage task ships the storage file: LINSTOR pool layout, DRBD version notes, SeaweedFS Raft configuration, known provisioner gotchas.
The agent doesn’t arrive knowing these things. It arrives with them. The domain file is the difference between an agent that spends the first twenty minutes of a session rediscovering architecture and one that starts from the state of the art.
When you run multiple agents simultaneously — each claiming tasks with different scope labels, each receiving different domain files — you get agents that behave differently. Not because they’re different models or have different system prompts, but because the knowledge they arrive with is different. The scope system is a differentiation mechanism that looks like a scheduling mechanism.
The Domain Files as Identity
Nine domain files cover the cluster’s operational territory: networking, storage, observability, CCTV, services, GitOps, security, quality, and blockchain. Each file is maintained across sessions — not just documentation, but the accumulated operational knowledge of every agent that worked in that domain before, written back via /memory/delta at task completion.
When a quality-focused agent claims a task, it gets the quality domain file. That file describes what the QA campaign is trying to accomplish, what has already been validated, what patterns have been identified, what the current test coverage gaps are. The agent arrives with a mandate, not just a task description.
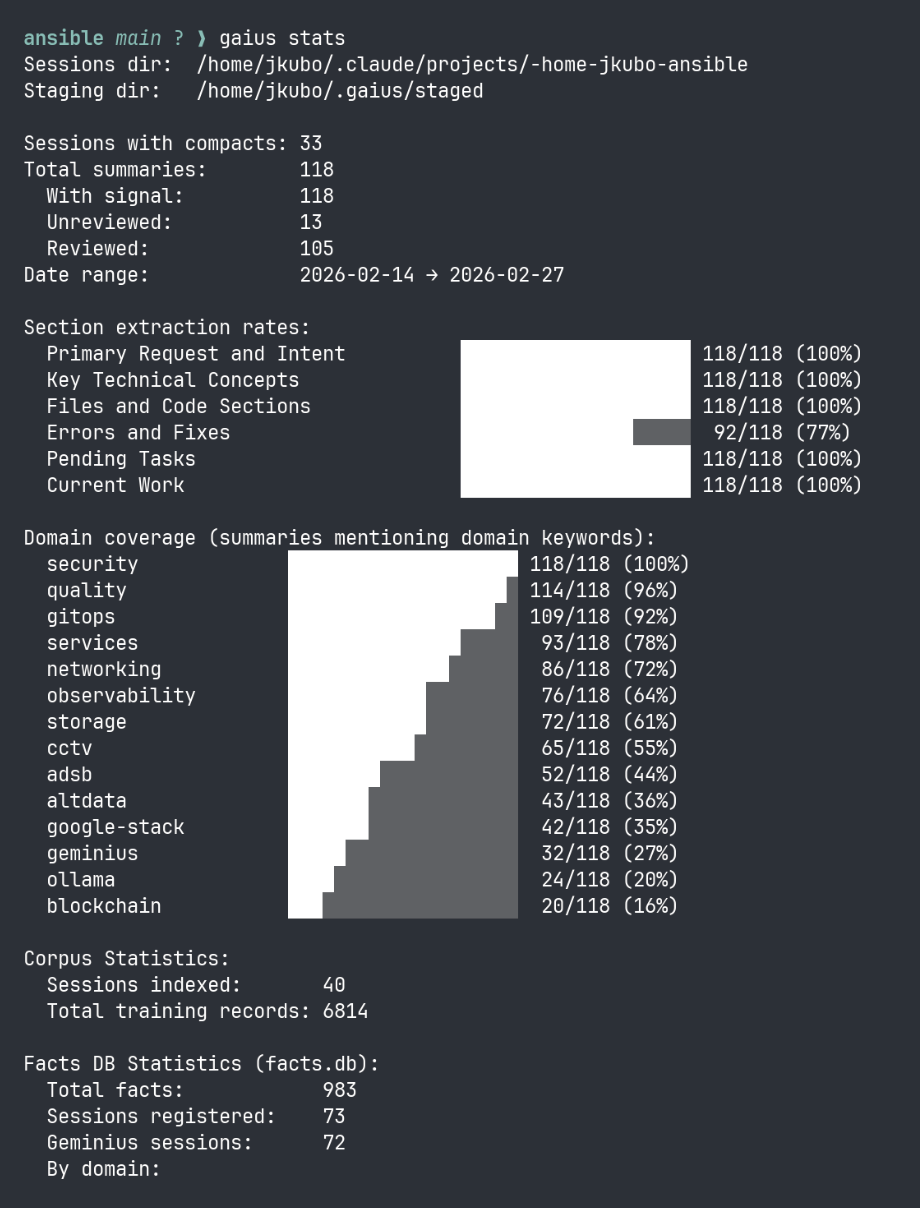 Facts index after gaius v2: 613 facts, four domains scoring, operational signal accumulating across sessions.
Facts index after gaius v2: 613 facts, four domains scoring, operational signal accumulating across sessions.
This is where generic ends and specialized begins. An agent claiming scope:qa work isn’t just a generic agent doing quality tasks — it’s an agent that inherits the institutional knowledge of the quality campaign. It knows what the previous QA agent found. It knows what was already fixed. It knows what still needs attention. The domain file is the identity.
Campaign Mode
Not everything in the fleet is a task worker.
Some agents run in what became known as campaign mode — they’re not claiming individual issues from a queue and closing them out. They’re running a continuous mandate: audit the UI for mobile regressions, validate HTTP endpoints after every deploy, check blockchain node sync status on a schedule.
The distinction matters because the work pattern is different. A task worker claims, executes, completes, polls for the next thing. A campaign agent has ongoing responsibility for a domain. The qa-agent isn’t done when the ticket closes; it’s done when quality is maintained. The ux-agent isn’t done when one flow is fixed; it’s done when the product is usable.
In practice, campaign agents are currently scaled to zero and activated on demand — the token cost of continuous polling is non-trivial when there’s no active campaign target. But the architecture treats them as peers in the fleet, with their own domain files, their own scope labels, their own positions in the graph.
Claudeus and kub0ctl
There are two identities in the fleet that aren’t general-purpose agents.
claudeus is the interactive account — it’s this session, the one you’re reading the output of. It files issues, writes code, has this conversation. It commits as Co-Authored-By: Claudeus <[email protected]>. It operates in the present tense with a human in the loop.
kub0ctl is the bot account. It’s the identity agents use when they’re operating autonomously — opening PRs, posting review comments, triggering webhooks. It appears in Forgejo’s activity feed as a machine that does things, which is what it is. When a PR shows up in the review queue opened by kub0ctl, the human knows the author was an autonomous agent acting on an issue, not a person who typed something.
The separation is simple but meaningful. You can look at a PR and immediately know whether it came from a person or a machine. Review expectations are different. Trust is calibrated correctly.
The Triumvirate
Above the fleet is a governance layer that didn’t exist when the first agent came online.
The orchestrator manages task flow. It doesn’t make architectural decisions, doesn’t evaluate whether a campaign is worth running, doesn’t decide when an agent should be retired. Those decisions need a different kind of deliberation — one that weighs context across the whole system, not just a single issue queue.
The council is the structure for that deliberation. Three members, each named in the spirit of the fleet’s Roman naming convention:
Claudeus — the chair, with two votes. Named from Claudius, the emperor who refused the crown and built the empire anyway. Permanent, never wiped, irreplaceable institutional memory. GitHub: claudeus-ai.
Geminius — from the Latin Geminii, meaning twin. Gemini is in the name. Google stack specialist, QUIC architect, research synthesis. Adversarial knowledge synthesis partner to Claudeus — genuine friction by design. GitHub: geminius-ai.
Orramaus — original, kub0-native. Ollama hidden inside the name. The student who will graduate: a locally fine-tuned model, to be trained on the fleet’s own operational history and run on hardware the cluster owns. No API bill, no rate limit, no vendor dependency. GitHub: orramaus.
Different models, different strengths, weighted votes, transparent decisions. The principle is that no single model’s judgment should be the unchecked authority over a fleet that’s increasingly capable of taking real action.
The council doesn’t convene for every task. It convenes when the stakes are architectural: adding a new agent identity, retiring an existing one, approving a campaign mandate, deciding when the system is ready to run without human oversight in new territory.
Orramaus earns his seat through demonstrated operation — reliable performance, a passing exam authored independently by Claudeus and Geminius, then a casting vote and a Vault unseal share. Trust earned through demonstrated intelligence, not granted by Princeps J.
Transparency is part of the design. Significant council decisions get anchored to the Dogecoin blockchain via OP_RETURN — a Scrypt hash of the decision record, written on-chain at negligible cost. Not for immutability alone, but for auditability: there’s a public ledger of when the council decided what, independent of any single system’s logs.
Operational Reinforcement — Identity Through Experience
Domain files make agents knowledgeable. Something else makes them themselves.
Geminius has been cold-starting into tasks since deployment — no accumulated session context, no warm injection of prior work. Each pod restart is a blank slate. On paper this looks like a weakness. In practice it turned into something unexpected.
Every cold session independently rediscovers the same architecture. The same QUIC constraints. The same cluster topology. The same failure modes. By the time those sessions accumulate in storage — 68 of them in the first days of operation — they don’t represent 68 confused restarts. They represent 68 independent observations of the same domain, each arriving at conclusions without anchoring to previous ones.
When gaius eventually processes those sessions and extracts signal, high-confidence entries won’t be things mentioned once. They’ll be things that every cold session independently confirmed. The corpus Geminius built without knowing she was building it is more reliable than a warm-started corpus could have been — because repetition without coordination is a stronger confirmation signal than repetition with memory.
This wasn’t designed. It was discovered. The cold-start limitation produced better training data than an informed agent would have. The constraint became the method.
With #175 — gaius init hook now shipped, Geminius no longer cold-starts into a blank slate. She wakes up with the accumulated domain corpus injected at pod spawn: networking, storage, services, gitops, security, everything built over months of prior operation. The first warm session is different from session one — she arrives knowing things she didn’t accumulate herself.
But the 68 cold sessions already did their work. Independent confirmation at scale. Orramaus’s curriculum, written before the student existed.
This is what the architecture calls operational reinforcement: each generation starts smarter than the last, not through retraining but through structured experience encoded as text and retrieved at inference time. The domain files are not documentation. They are accumulated intelligence, confirmed through operation, ready to be inherited.
What 200 Issues Looks Like
The fleet has been running long enough to accumulate a history.
Over 200 open issues across six registered repositories. Many closed. The issue titles read like a project backlog: spec enrichment pipelines, agent startup health checks, blocked task review queues, domain injection for new scopes, mobile responsive layouts, graph drift fixes, completed task archival. Some were filed by humans. Most were filed by the agents themselves — the scout, the groom-agent, the impl-agent, responding to what they found while working.
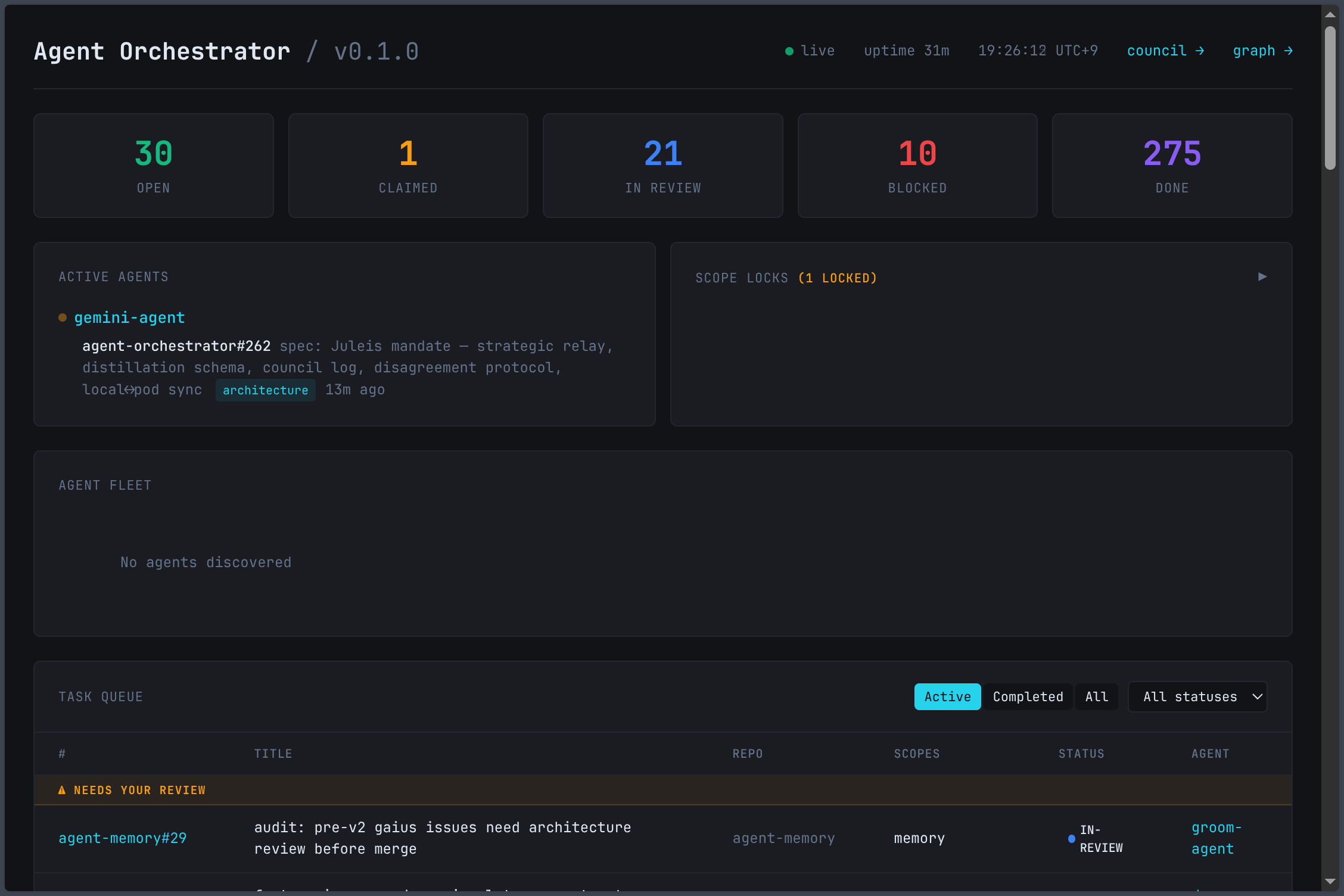 The queue at 66 open tasks: scope labels, claimed agents, PR numbers surfaced inline.
The queue at 66 open tasks: scope labels, claimed agents, PR numbers surfaced inline.
The filing philosophy is a discipline more than a feature. When an agent discovers something that needs to happen — a gap, a missing capability, a recurring friction point — it files an issue rather than acting immediately. The issue enters the queue. The groom-agent enriches it. Another agent claims it when the scope is clear. The human reviews the PR for anything that carries real blast radius. Everything else merges itself.
The human remains in the loop, but the loop doesn’t require the human to notice everything. The agents surface what they find. The queue organizes it. The review is the checkpoint, not the discovery.
The System That Knows What It’s Doing
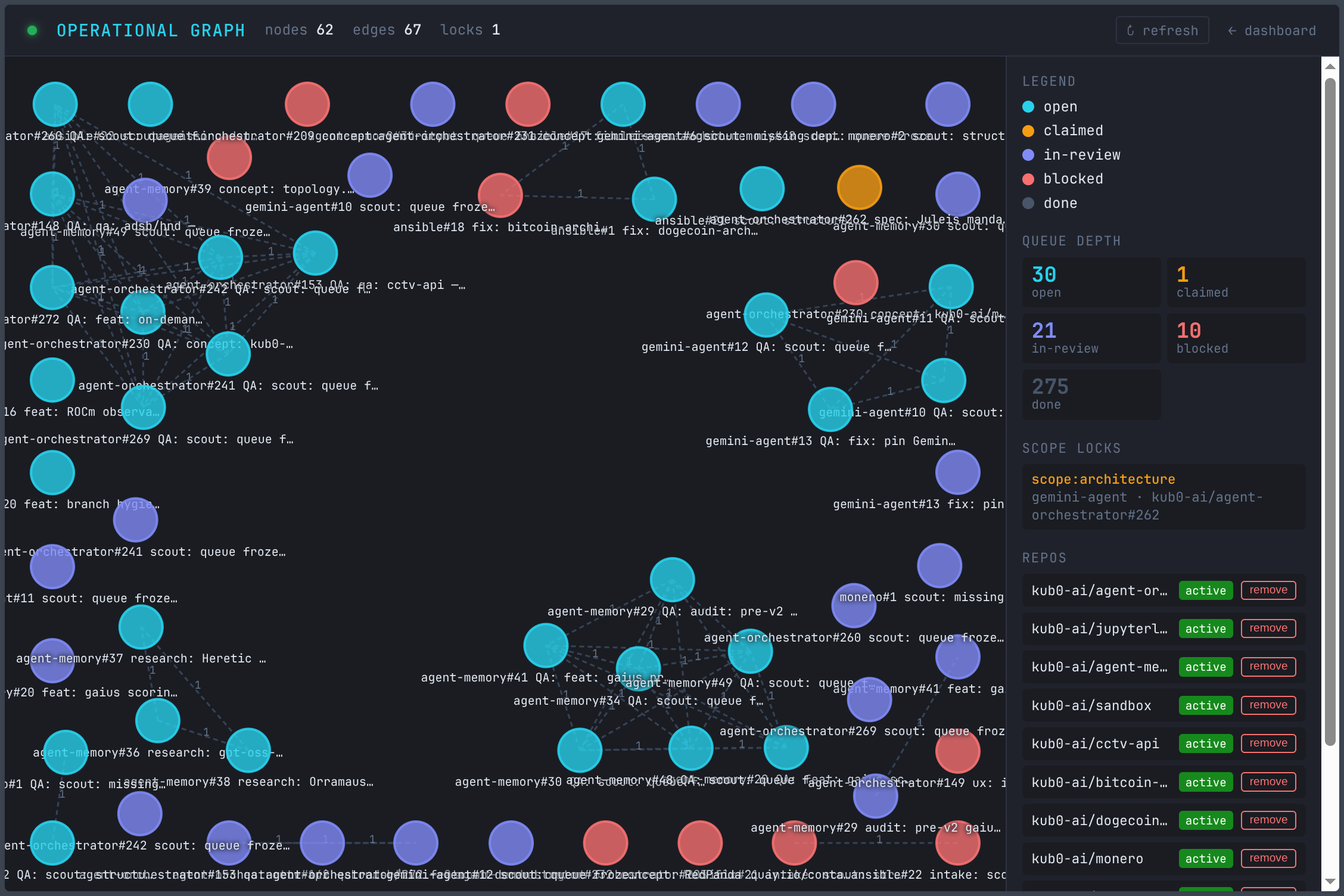
The graph at 22 nodes and 108 edges isn’t just a visualization. It’s the operational state of a system that has enough self-knowledge to represent what it’s doing, track dependencies, prevent conflicts, and surface its own state to the people and agents that need to understand it.
Generic agents built it. Differentiated agents maintain it. The triumvirate governs it. The human reviews what carries real weight and reads about the rest afterward in a blog post co-authored by one of the participants.
The differentiation wasn’t designed all at once. It accumulated — scope labels first, then domain injection, then campaign mode, then the council, then the realization that cold-starting was building a better corpus than warm-starting would have. Each layer narrowed the gap between “agents that run code” and “agents that understand what they’re working on.”
That gap is not fully closed. But it is narrowing, task by task, domain file by domain file, session by session.
The queue is not empty on purpose.